================前言===================
-
初衷:网上已有很多关于 MobX 源码解读的文章,但大多阅读成本甚高。本人在找文章时对此深有体会,故将以系列故事的方式展现源码逻辑,尽可能以易懂的方式讲解 MobX 源码;
-
本系列文章:
-
文章编排:每篇文章分成两大段,第一大段以简单的侦探系列故事的形式讲解(所涉及人物、场景都以 MobX 中的概念为原型创建),第二大段则是相对于的源码讲解。
-
本文基于 MobX 3 源码讲解
=======================================
A. Story Time
1、 场景
场景:
一位名为 张三 的银行用户账户情况为:
- 账户存款为 3(万元)
- 信用借贷为 2(万元)
你作为警署最高长官,在一起金融犯罪中认定 张三 为金融犯罪嫌疑犯,想自动化跟踪这位用户的储蓄情况,比如他一旦银行存款有变更就打印出他当前的账户存款
为了实现这个任务,你下发命令给你的执行官(MobX):
var bankUser = mobx.observable({
name: '张三',
income: 3,
debit: 2
});
mobx.autorun(() => {
console.log('张三的账户存款:', bankUser.income);
});

执行官拿着这几行代码开始部署警力来完成你下发的指令,并将这次行动命名为 A计划 (是不是很酷???)。你所要做的,就是等执行官 MobX 执行行动部署完毕之后,坐在办公室里一边惬意地喝着咖啡,一边在电脑上观察张三账户的存款变化。
执行官部署完毕后,首先会立即打印出 张三的账户存款: 3
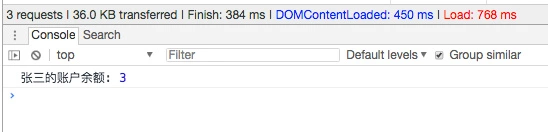
后续张三的账户存款有更改的话,会 自动执行该部署方案,控制台里就自动打印其存款;
// 更改账户存款
bankUser.income = 4;
bankUser.income = 10;
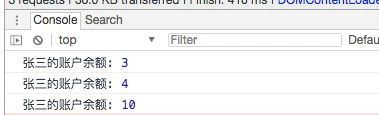

是不是很神奇很自动化?
2、 部署方案
作为警署最高长官,你不必事必躬亲过问执行官(MobX)部署的细节,只要等着要结果就可以。
而作为执行官(MobX),你得知道 A计划 中部署方案的每一步细节。下面我们来一探究竟执行官 MobX 到底是如何部署 A计划 的。
2.1、 组织架构
执行官(MobX) 拥有一套成熟的运作机构组织支撑任务的执行。为了执行这项任务,涉及到 2 类职员和 1 个数据情报室:
-
观察员:其工作职责是观察并监督嫌疑人特定信息,比如这里,监视张三的收入(
income)属性,当这项特征有变更的时候,及时向上级汇报(并执行特定的操作);

-
探长:一方面负责管理划归给他的 观察员,整合观察员反馈的资讯;另一方面接受 MobX 执行官交给他的任务,在 适当的时机 执行这项任务(此任务是打印张三的存款);

-
此外还会架设一个 数据情报室,方便执行官 MobX、探长和观察员们 互相通过情报室进行数据信息的交换。

具体组织架构关系图如下:
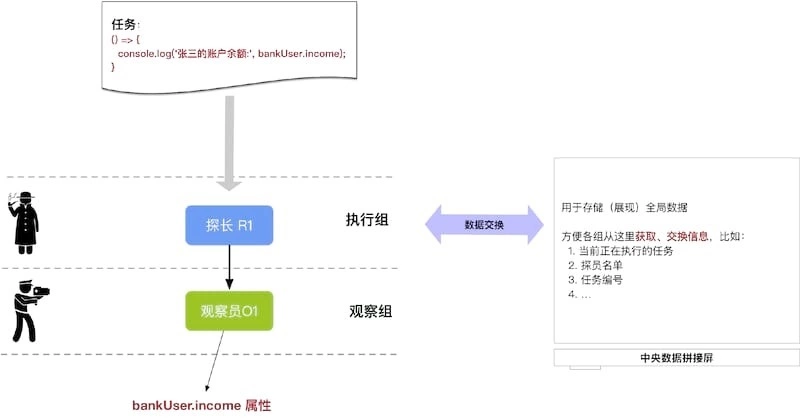
按照组织架构,执行官 MobX 分解计划细节并安排人员如下:
1.明确此次任务是 当张三账户存款变更时,打印其存款:
() => {
console.log('张三的账户存款:', bankUser.income);
}
2.将任务指派给执行组中的探长 R1
3.派遣观察组中的观察员 O1 监察张三账户的 bankUser.income 属性
4.探长 R1 任务中所需的“张三的账户存款” 数值必须从观察员 O1 那儿获取;
5.同时架设数据情报室,方便信息交换;
2.2、 部署细节
人员安排完毕,执行官拿出一份 部署方案书,一声令下 “各位就按这套方案执行任务吧!”;
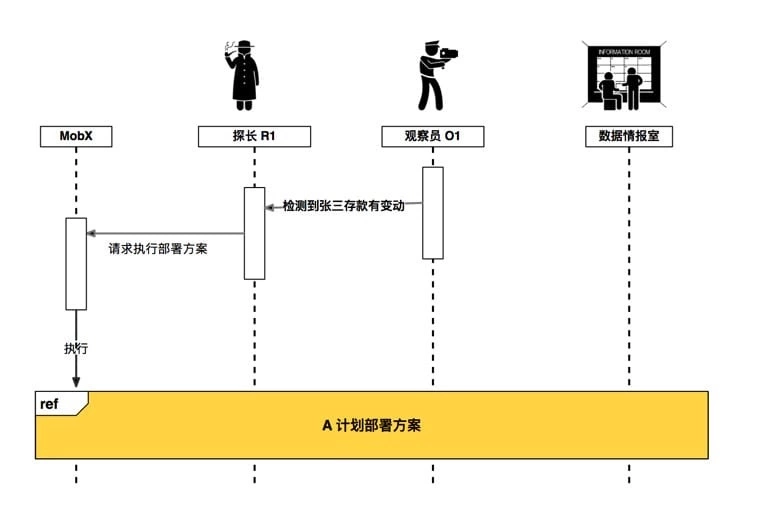
在部署方案中下达之后,机构各组成员各司其职,开始有条不紊地开始运作,具体操作时序图如下所示:
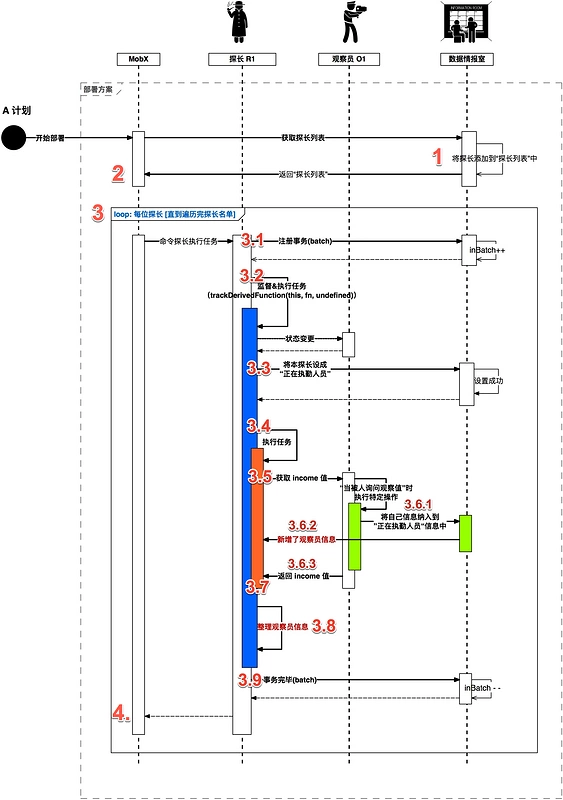
对时序图中的关键点做一下解释:
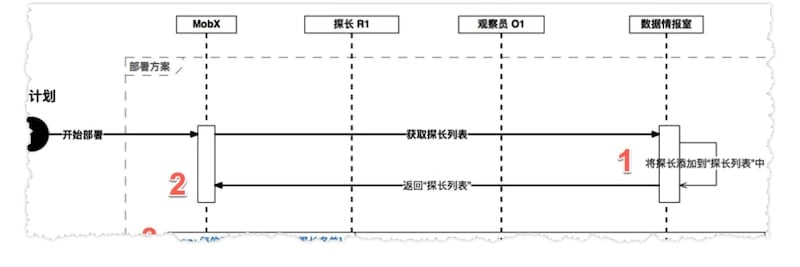
- 执行官 MobX 先将探长 R1 信息注册到中心情报室;(有些情况下,比如侦破大案要案时需要多位探长协作,将存在多位探长同时待命的情况;当然此次任务中,只有探长 R1 在待命)
- 中心情报室给执行官 MobX 返回所有待命探长列表(此例中仅有探长 R1);
- 执行官 MobX 挨个让每位待命探长按以下步骤操作:
- 3.1. 探长出发做任务时,记得给中心情报室通告一声,好比上班“打卡”操作。(记录事务序号,好让中心情报室知晓案情复杂度;有些案件中将有很多探长同时执行任务)
- 3.2 探长 R1 开始监督并执行 MobX 交给他的任务(“打印张三的存款”)
- 3.3 首先在数据情报室中“注册”,将自己设置成 正在执勤人员;(这一步很重要)
- 3.4 随后真正进入执行任务的状态
- 3.5 在执行任务的时候,发现需要张三的存款(
income)这个数值,可这个数值探长 R1 不能直接获取,必须通过观察员 O1 取得,于是通过专用通讯机和观察员 O1 取得联系,请求获取要张三的存款(income) - 3.6 观察员 O1 发现有人通过专用通讯机请求张三的存款(
income),就开始如下操作:- 3.6.1 将自己的信息 经过 数据情报室,然后传达给请求方;只有上级(不一定是探长,有可能是其他的上级领导)才能通过这个专用通讯机发消息给观察员;
- 3.6.2 数据情报室 将该信息同步给 正在执勤人员 —— 即探长 R1
- 3.6.3 同时将张三的存款(
income)返回给请求方;(该消息不用经过 数据情报室)
- 3.7 此时探长拥有两份信息:任务所需要的张三的存款(
income),以及观察员 O1 的相关信息;因时间紧,执行任务优先级高,探长 R1 先拿着张三的存款(income)数据,先做完任务。(至于观察员 O1 的信息 先临时保存 ,方便后续处理); - 3.8 等到任务执行完了,探长松了一口气,汇总并整理临时保存的观察员信息;在这一阶段,探长 R1 才和 观察员 O1 互相建立牢固的关系(可以理解为,互留联系方式,可随时联系得上对方),也是在这个时候,观察员 O1 才知晓其上级领导是探长 01;
- 3.9 此后,探长 R1 发消息告知中心情报室,削去此次事务(说明事务执行完了),好比下班 “打卡”操作。
- 至此 A 计划部署完毕
上述时序图中有些地方需要强调一下:
-
张三的存款(
income)只归观察员 O1 监视,探长 R1 所获取的张三的存款只能通过观察员 O1 间接获取到,探长不能越权去直接获取; -
探长 R1 和观察员 O1 建立关系并非一步到位,是 分两个阶段 的:
- 第一阶段(对应上述步骤中 3.6.2)是在执行任务期间,仅仅是建立短暂的 单向关系;即,此时探长 R1 知晓观察员 O1 的情况,但反过来,但观察员 O1 并不知晓探长 R1 ;
- 第二阶段(对应上述步骤中 3.8)在任务执行完,收尾阶段的时候,探长才有时间梳理、整合任务期间的探员信息(因为任务中涉及到有可能多个观察员,当然此次任务中只有 1 个),那时候才有时间 慢慢地 和各位探员互相交换信息,建立 明确且牢固 的关系;
2.3、 任务执行自动化
作为警署最高长官的你,拿着这份部署方案,眉头紧锁:“我说执行官 ,就为了区区获取张三的存款这么件事儿,耗费那么多人力资源,值么?直接获取 bankUser.income 不就行了?!”
“emm...,这所做的努力,图的是普适性和 自动化响应。”执行官 MobX 淡然自如,不紧不慢徐徐道来,“有了上面那套机制,一方面每当张三的存款变更后,就会 自动化执行上述部署方案的过程;另一方面很方便扩展,后续针对其他监察,只需要在此部署方案中稍加改动就可以,所需要的高级功能都是基于这个方案做延伸。真正做到了 ’部署一次,全自动化执行‘ 的目的。“
随后,执行官 MobX 给出一张当张三存款发生变化之时,此机构的运作时序图;
"的确,小机构靠人力运作,大机构才靠制度运转。那就先试运行这份部署计划,看它能否经受得起时间的考验吧。" 警署最高长官拍拍执行官 MobX 的肩膀,若有所思地踱步出了办公室。
(此节完。未完待续)
B. Source Code Time
上面讲那么久的故事,是为了给讲源码做铺垫。
接下来将会贴 MobX 源码相关的代码,稍显枯燥,我只能尽量用通俗易懂的话来分析讲解。
先罗列本文故事中人物与 MobX 源码概念映射关系:
| 故事人物 | MobX 源码 | 解释 |
|---|---|---|
| 警署最高长官 | (无) | MobX 用户,没错,就是你 |
| 执行官 MobX | MobX | 整个 MobX 运行环境 |
| A计划 | autorun | 官方文档 -mobx.autorun方法 |
| 探长 | reaction | 官方文档 - Reaction 响应对象 |
| 观察员 | observable | 官方文档 - Observable 对象 |
| 数据情报室 | globalstate | MobX 运行环境中的 ”全局变量“,不同对象通过它进行数据传递通信,十分重要;(但这其实在一定程度上破坏了内聚性,给源码阅读、程序 debug 造成一定的难度) |
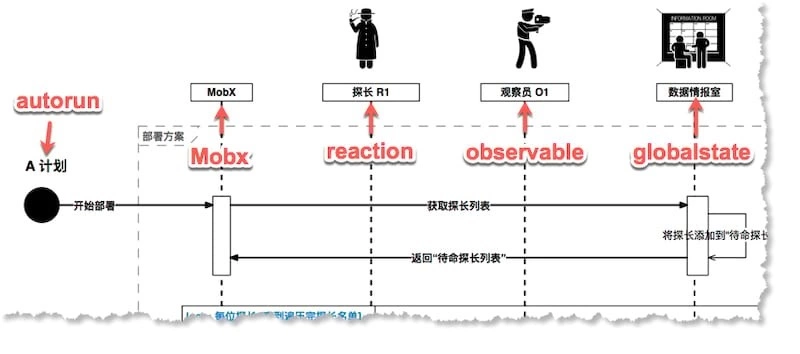
本文的重点是讲解 A 计划所对应的 autorun 的源码,先从整体上对 MobX 的运行有个大致了解,而所涉及到的 Reaction、Observable 等细节概念后续章节再做展开,这里仅仅大致提及其部分功能和属性;
1、下达的命令
回到故事的最开始,你给 MobX 下达的命令如下:
var bankUser = mobx.observable({
name: '张三',
income: 3,
debit: 2
});
mobx.autorun(() => {
console.log('张三的账户存款:', bankUser.income);
});
只有两条语句,第一条语句是创建观察员,第二条语句是执行 A 计划(内含委派探长、架设情报局等工作)
我们挨个细分讲解。
1.1、第一条语句:创建观察员 - Observable
第一条语句:
const bankUser = mobx.observable({
name: '张三',
income: 3,
debit: 2
})
我们调用 mobx.observable 的时候,就创建了 Observable 对象,对象的所有属性都将被拷贝至一个克隆对象并将克隆对象转变成可观察的。
因此这一行代码执行后, name、income 和 debit 这三个属性都变成可观察的;
若以故事场景来叙述中,执行官 MobX 在部署的时候委派了 3 位探员,分别监视这 3 个属性;而故事中交给探长任务中仅仅涉及了那位监视 income 属性的观察员 O1;(所以另外两位探员都还在休息)
在这里可以看到 惰性求值 的思想的应用,只有在 必要的时候 启用 所观察对象,粒度细,有利于性能提升;
之所以只有 1 位观察员,是因为由于上级下达的具体任务内容是:
() => {
console.log('张三的账户存款:', bankUser.income);
}
看看任务中出现 bankUser.income 而并没有出现 bankUser.debit 和 bankUser.name,说明这个任务只 牵连 探员O1,而和其他探员无关。
注:本文暂时先不分析
mobx.observable的源码,留待后续专门的一章来分析;迫不及待的读者,可以先阅读网上其他源码文章,比如:Mobx 源码解读(二) Observable
观察员有两个非常重要的行为特征:
- 当有人请求观察员所监控的值(比如
income)时,会触发 MobX 所提供的reportObserved方法; - 当观察员所监控的值(比如
income)发生变化时,会触发 MobX 所提供的propagateChanged方法;
这里留一个印象,本文后续在适当的时机再讲解这两个方法是在什么时候触发的;
1.2、第二条语句:A 计划的实施 - autorun
第二条语句:
mobx.autorun(() => {
console.log('张三的账户存款:', bankUser.income);
});
这里出现的 MobX 中的 mobx.autorun 方法对应故事中的 整个A计划的实施:
autorun 的直观含义就是 响应式函数 —— 响应观察值的变化而自动执行指定的函数。
我们看一下其源码:
附源码位置:autorun
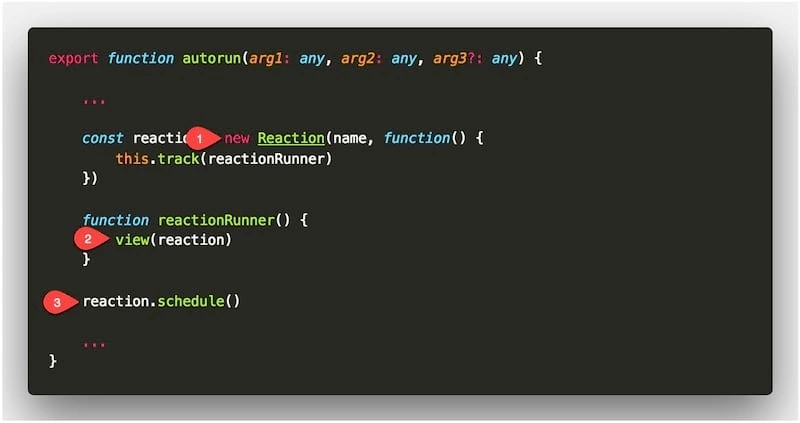
从这里可以看出 autorun 大致的脉络如下:
① 首先创建 Reaction 类型对象。new Reaction 操作可以理解为创建探长 R1 ;
探长对应的类是 Reaction,其关键特征是 监督并控制任务的执行;
本文的下一节将详细介绍探长们的 "生活日常",此处先放一放。
② 其次分配任务。源码中所涉及到的 view() 方法 就是具体的任务内容,即上述故事中的 打印张三账户存款 这项任务:
() => {
console.log('张三的账户存款:', bankUser.income);
}
③ 最后,立即执行一次部署方案。
代码中的 reaction.schedule() 表示让探长 R1 立即执行执行一次部署任务,执行的结果是完成人员部署,并让探长 R1 打印了一次张三账户存款;(同时和观察员 O1 建立关系)
现在你应该会理解官方文档中的那句 ”使用 autorun 时,所提供的函数总是立即被触发一次“ 话了。

看一下 schedule 方法:
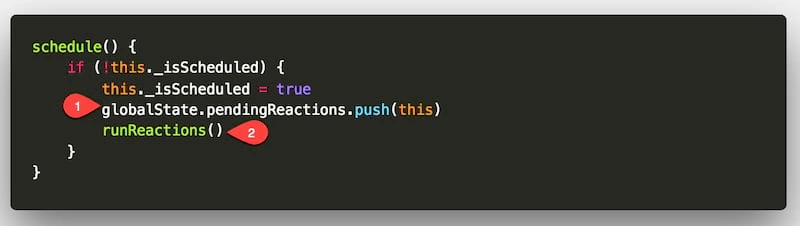
看上去很简单,不到 5 行代码做了两件事情:
① 将探长入列;
② 让队列中的 所有探长(当然,在我们的示例中仅仅只有 1 名探长)都执行 runReaction 方法
对应时序图中所标注的 1、2 两部分:
所谓的 部署(schedule) 就是敦促 各位探长执行 runReaction 方法。
第二条语句从整体上看就这样了。
接下来就让我们来详细分析探长的 runReaction 的方法,在该方法中 探长将联动观察员、数据情报室一起在部署方案中发挥监督、自动化响应功能。
2、每位探长的生活日常
任务的执行全靠探长,不过探长的存在常常是 依赖观察员 的,这是因为在任务过程中,如果想要获取所监视的张三的存款(income),必须通过观察员获取,自身是没有权力绕过观察员直接获取的哦。
每位探长的任务执行流大致如下:
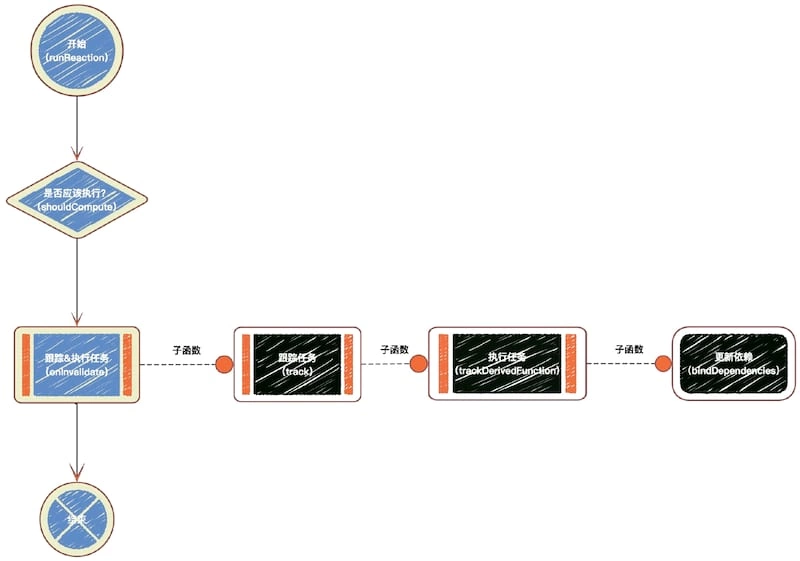
主流程大致只有 4 步:
① 开始执行(runReaction)
② 判断是否执行(shouldCompute)
③ 执行任务(onInvalidate)
④ 结束
这些基就是每位探长的生活的总体了。下面我们挑其中的第 ① 、 ③ 步来讲解。
其实图中另外有一个很重要的 shouldCompute 判断方法步骤,根据这个方法探长可以自行判断 是否执行任务,并非所有的任务都需要执行,这一步的作用是优化 MobX 执行效率。该方法源码内容先略过,后续章节再展开。
2.1、开始执行 - runReaction
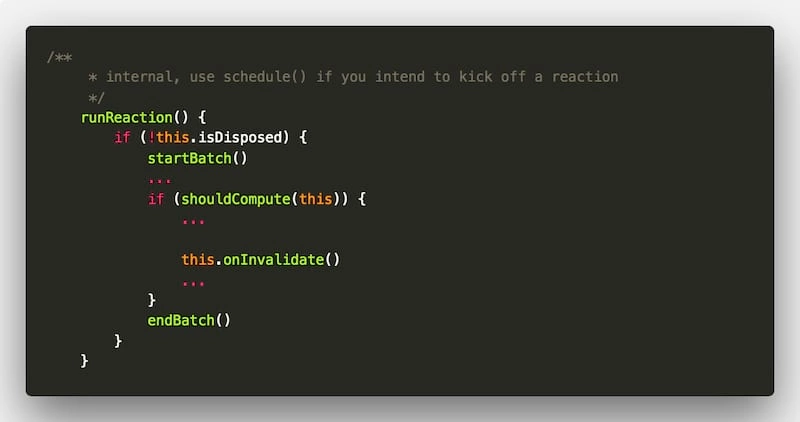
该函数比较简单,主要是为执行任务 ”做一些准备“,给任务营造氛围。用 startBatch() 开头,用 endBatch() 结尾,中间隔着 onInvalidate。
startBatch() 和 endBatch() 这两个方法一定是成对出现,用于影响 globalState 的 inBatch 属性,表明开启/关闭 一层新的事务,可以理解为 上下班打卡 操作。
只不过 startBatch() 是 ”上班打卡“,对应时序图(3.1) 部分:

endBatch() 相当于 “下班打卡”,不过稍微复杂一些,包含一些 收尾 操作,对应时序图(3.9)部分:

我们继续看隔在中间的 onInvalidate 方法。?
2.2、执行任务 - onInvalidate
此阶段是流程中最重要的阶段。
你翻看源码,将会发现此方法 onInvalidate 是 Reaction 类的一个属性,且在初始化 Reaction 时传入到构造函数中的,这样做的目的是方便做扩展。
所以,autorun 方法本质就是一种预定义好的 Reaction —— 你可以依葫芦画瓢,将自定义 onInvalidate 方法传给 Reaction 来实现自己的 计划任务(什么 Z计划啊、阿波罗计划啊,名字都起好了,就差实现了!!....);
回过头来,在刚才所述的 autorun 源码中找到 Reaction 类初始化部分:
const reaction = new Reaction(name, function() {
this.track(reactionRunner)
})
可以看到 onInvalidate 方法就是:
function() {
this.track(reactionRunner)
}
这就不难理解 onInvalidate 实际执行的是 reaction.track 方法。
继续跟踪源码,会发现该 onInvalidate 阶段主要是由 3 个很重要的子流程所构成:
- 3.1 跟踪任务(track)
- 3.2 执行任务(trackDerivedFunction)
- 3.3 更新依赖(bindDependencies)
这 3 个函数并非是并行关系,而是嵌套关系,后者是嵌套在前者内执行的:
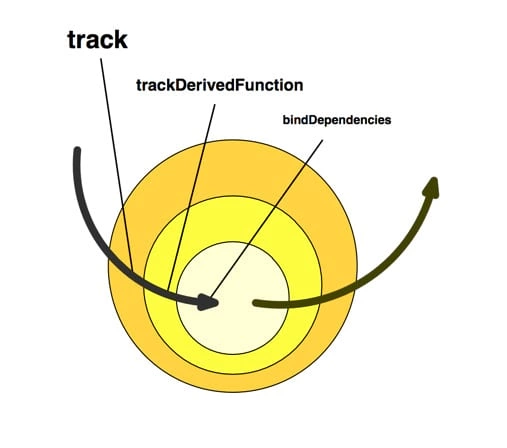
题外话:是不是很像 Koa 的 洋葱圈模型 ??
2.2.1、track
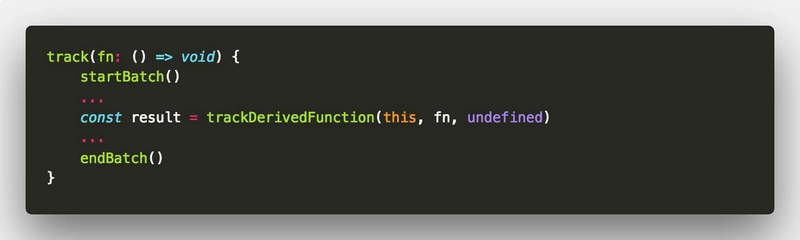
track 方法内容也简单,和刚才所说的 runReaction 方法类似 —— 也是用 startBatch() 开头,用 endBatch() 结尾,中间隔着 trackDerivedFunction。
所以在这个案例中,整个部署阶段是执行 两次 startBatch() 和 endBatch() 的;在往后复杂的操作中,执行的次数有可能更多。
我们都知道数据库中的事务概念,其表示一组原子性的操作。Mobx 则借鉴了 事务 这个概念,它实现比较简单,就是通过 成对 使用 startBatch 和 endBatch 来开始和结束一个事务,用于批量处理 Reaction 的执行,避免不必要的重新计算。
因此到目前这一步,MobX 程序正处在 第二层 事务中。
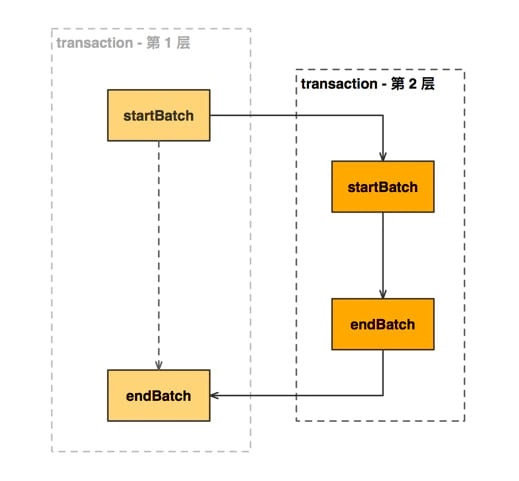
MobX 暴露了 transaction 这一底层 API 供用户调用,让用户能够实现一些较为高级的应用,具体可参考 官方文档 - Transaction(事务) 章节获取更多信息。
接下来继续看隔在中间的 trackDerivedFunction 方法。?
2.2.2、trackDerivedFunction
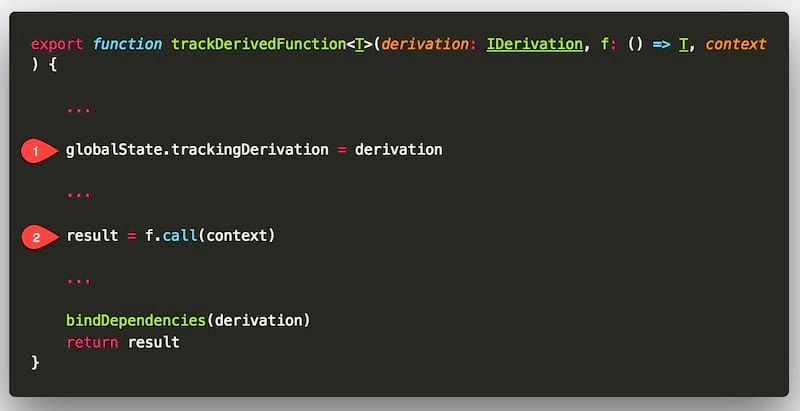
我们总算到了探长 真正执行任务 的步骤了,之前讲的所有流程都是为了这个函数服务的。
该环节的第 1 条语句:
globalState.trackingDerivation = derivation;
对应时序图(3.3):

作用是将 derivation (此处等同于 reaction 对象)挂载到 ”全局变量“ globalState 的 trackingDerivation 属性上,这样其他对象就能获取到该 derivation 对象的数据了。这好比将探长在数据情报室中注册为 正在执勤人员,后续观察员 O1 会向数据情报室索取 正在执勤人员 人,然后将自身信息输送给他 —— 从结果上看,就相当于 观察员 O1 直接和 探长 R1 汇报;(之所以要经由数据情报室,是因为在执行任务时候,有可能其他工种的人也需要 正在执勤人员 的信息)
该环节的第 2 条语句:
result = f.call(context); // 效果等同于 result = console.log('张三的账户存款:', bankUser.income);
对应时序图(3.4):

没错,就是本次部署的 终极目的 —— 打印张三账户存款!
MobX 将真正的目的执行之前里三层外三层地包裹其他操作,是为了将任务的运行情况控制在自己营造的环境氛围中。为什么这么做呢?
这么做是基于一个前提,该前提是:所运行的任务 MobX 它无法控制(警署长官今天下达 A 命令,明天下达 B 命令,控制不了)。
所以 MobX 就将任务的执行笼罩在自己所营造的氛围中,改变不了任务实体,我改变环境总行了吧?!!
由于环境是自己营造的,MobX 可以为所欲为,在环境中穿插各种因素:探长、观察员、数据情报室等等(后续还有其他角色),这样就将任务的运行尽最大可能地控制在这套所创造的体系中 —— 孙猴子不也翻不出如来佛的五指山么?
虽然更改不了任务内容,不过 MobX 实际在任务中安插观察员 O1 了,所以呢,当探长在执行任务时,将触发时序图中 (3.5)(3.6)两步反应:

复杂么?也还好,(3.6)是由 (3.5)触发的,(3.5)对应的操作是:探长 R1 想要获取的张三 income 属性。
(所以,划重点,敲黑板!! 如果任务中不涉及到 income 这项属性,那么就不会有 (3.5)的操作,也就没有 (3.6)什么事)
由于探长 R1 所执行的任务中用到 bankUser.income 变量,这里的 . 符号其实就是 get() 操作;一旦涉及到 get() 操作,监督这个 income 属性的观察员 O1 就会执行 reportObserved 方法。 该 reportObserved 方法对应的源码如下:
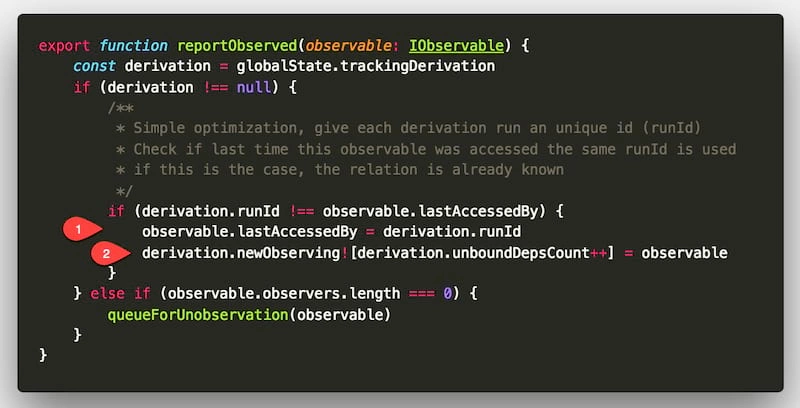
那么多行代码,我们主要关注其中操作影响到探长(derivation)中的操作:
-
- 更新探长的
lastAccessedBy属性(事务 id),这个是为了避免重复操作而设置的
- 更新探长的
-
- 更新探长的
newObserving属性,将探员信息推入到该队列中(对应时序图 (3.6.2)操作),这个比较重要,后续探长和观察员更新依赖关系就靠这个属性了;
- 更新探长的
随后,任务执行完(时序图(3.7))后,探长就开始着手更新和观察员 O1 的关联关系了。?
2.2.3、bindDependencies
探长 R1 整理和观察员的关系是在时序图 (3.8)处:
两者依赖更新的算法在参考文章Mobx 源码解读(四) Reaction 中有详细的注解,推荐阅读。这里也做一下简单介绍。
该函数的目的,是用 derivation.newObserving 去更新 derivation.observing 属性:
derivation.newObserving就是刚才在所述时序图 (3.6.2)操作是生成的- 执行完之后
derivation.newObserving会置空,而derivation.observing属性获得更新,该属性反映的 探长 和 观察员 之间最新的关联关系;
依赖更新肯定需要遍历,由于涉及到探长、观察员两个维度的数组,朴素算法的时间复杂度将是 O(n^2),而 MobX 中使用 3 次遍历 + diffValue 属性的辅助将复杂度降到了 O(n)。? ?
下面我用示例来展现这 3 次遍历过程。
2.2.3.1、先看一下整体的 input / output
假设在执行 bindDependencies 函数之前, derivation.observing 已有 2 个元素,derivation.newObserving 有 5 个对象(由于 A、B 各重复一次,实际只有 3 个不同的对象 A、B、C),经过 bindDependencies 函数后 derivation.observing 将获得更新,如下所示:
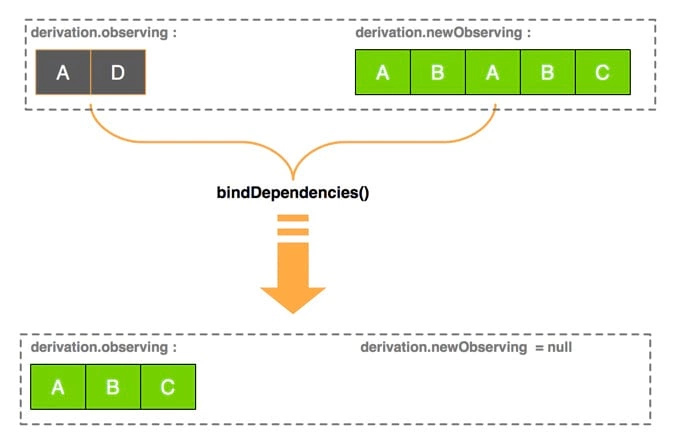
2.2.3.2、第一次循环:newObserving 数组去重
第一次循环遍历 newObserving,利用 diffValue 进行去重,一次遍历就完成了(这种 数组去重算法 可以添加到面试题库中了??)。注意其中 diffValue 改变情况:
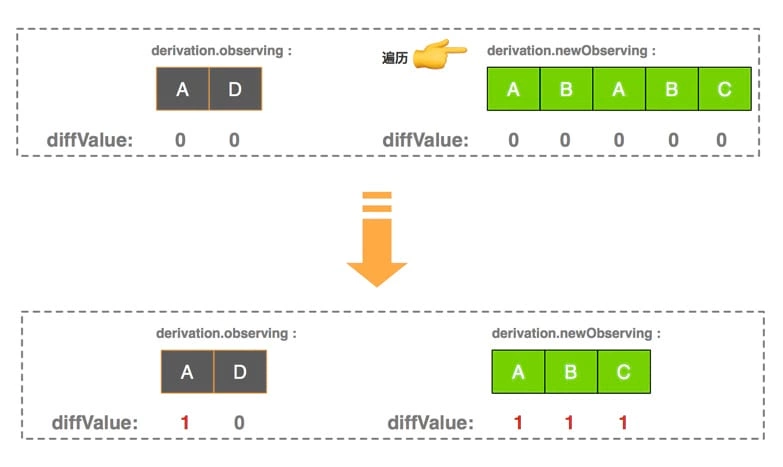
由于 A 对象(引用)既在
observing数组也在newObserving数组中,当改变newObserving中 A 元素的diffValue值的时候,observing数组 A 属性也自然跟着改变;
这次遍历后,所有 最新的依赖 的 diffValue 值都是 1 了哦,而且去除了所有重复的依赖。
2.2.3.3、第二次循环:去除observing 数组陈旧关联
接下去第二次遍历针对 observing 数组,做了两件事:
- 如果对象的
diffValue值为 0 (为 0 说明不在newObserving数组中,是陈旧的关联),则调用removeObserver去除该关联;因此这次遍历之后会删除observing数组中 D 对象 - 让
observing数组中剩余对象的diffValue值变成 0;
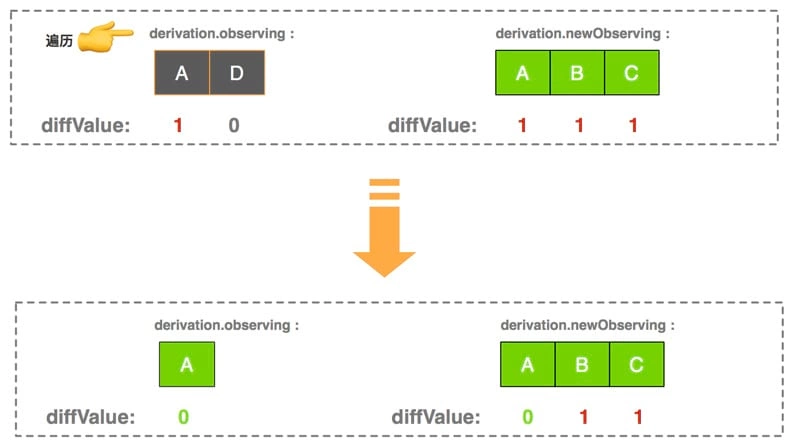
这一次遍历之后,去除了所有陈旧的依赖,且遗留下来的对象的 diffValue 值都是 0 了。
2.2.3.4、第三次循环:将新增依赖添加到 observing
第二次遍历针对 newObserving 数组,做了一件事:
- 如果
diffValue为 1,说明是新增的依赖,调用addObserver新增依赖,并将diffValue置为 0
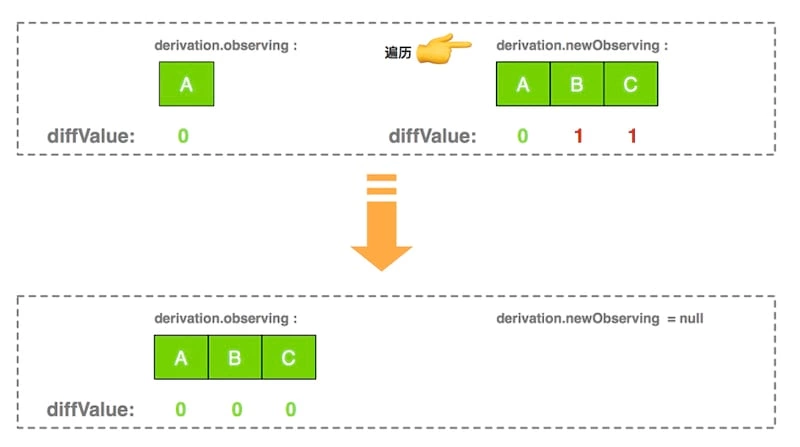
这最后一次遍历,observing 数组关联都是最新,且 diffValue 都是 0 ,为下一次的 bindDependencies 做好了准备。
至此,A计划部署方案(autorun 源码)就讲完了。 A 计划执行后,探长 R1 完成上级下达的任务,同时也和观察员 O1 建立起明确且牢固的依赖。
3、响应观察值的变化 - propagateChanged
一旦张三存款发生变化,那么一定会被观察员 O1 监视到,请问此时观察员会怎么做?
或许有人会说,观察员 O1 然后上报给探长 R1 ,然后让探长 R1 再执行一次打印任务;
从最终结果角度去理解,上面的陈述其实没毛病,的确是观察员 O1 驱动探长 R1 再打印一次;
但若从执行过程角度去看,以上陈述是 错误的! ?
观察员 O1 监视到变化之后,的确通知探长 R1了,但探长并非直接执行任务,而是通知 MobX 再按照 A 计划部署方案执行一遍!;(不得不感慨,这是多么死板地执行机制)
源码中是怎么体现的呢?
上面提及到过,当观察员所监控的值(比如income)发生变化时,会触发 MobX 所提供的 propagateChanged 方法。
propagateChanged 对应的源码如下:
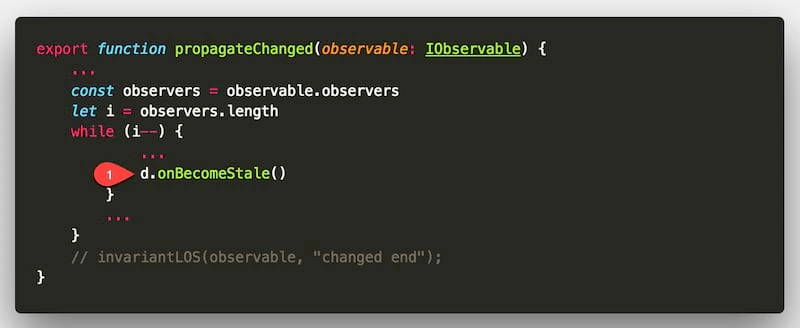
代码很简单,即遍历观察员的上级们,让他们调用 onBecomeStale() 方法 。该观察员有可能不止对一位上级(上级也不一定只有探长)负责,每位上级的 onBecomeStale() 是不一样的。(当然,此故事中观察员 O1 只有 1 位上级 —— 探长 R1)
我们看一下探长这类上级所定义的 onBecomeStale:
onBecomeStale() {
this.schedule()
}
简单明了,就是直接 再一次执行部署方案。如此简单朴素,真正做到了 “一视同仁” —— 无论什么任务,一旦部署就绪,任何观察员反馈情况有变(比如张三账户余额发生变动了),探长都是让 MobX 重新执行一遍部署方案,并不会直接执行任务,反正部署方案中有探长执行任务的步骤嘛。??
所谓的流程化、设计模式,都多多少少在一定程度上约束个体行为(丧失了一部分灵活性),而取得整体上的普适性和可扩展性。
现在再回过头来看刚才官方文档截图中的第二句话:"然后每次它的依赖关系改变时会再次被触发"

它所表达的意思其实就是:当张三余额发生变化的时候,将 自动触发 上述的 A 计划部署方案。
4、小测试
问:下列代码中 message.title = "Hello world" 为何不会触发 autorun 再次执行?
const message = observable({ title: "hello" })
autorun(() => {
console.log(message)
})
// 不会触发重新运行
message.title = "Hello world"
其实上述问题来自官方的一个问题,若无思路的,可以先参考官方文档 常见陷阱: console.log。如果能从源码角度回答这个问题,则说明已经理解本节所讲的 autorun 的知识点了
5、小结
此篇是开篇,所阐述的概念仅仅占 MobX 体系冰山一角。

故事中还还有很多问题,比如:
- 如何成为一名合格的探员、观察员?(用程序员的话讲,就是有哪些属性和方法)
- 数据情报室到底还存有哪些关键信息?
- 组织机构中是否还有其他组、成员?
- 多个探长、观察员情况下,这套部署方案又是如何的呢?
- ....
以上问题的答案,读者可能已经知道,那些还不知道的可以自己留作自己思考;在后续章节,我也会在适当的时机解答上述中的问题;
(也欢迎大家提问,将有可能采纳编入后续的故事叙述中来解答)
后续的章节中,将继续介绍 ComputedValue、Action、Atom、Derivation、Spy 等,正是这些功能角色使得 MobX 有着强大的自动化能力,合理运用了惰性求值、函数式编程等编程范式,使 MobX 在复杂交互应用中大放异彩;
-
官方中文文档:不多讲,官方文档最好翻一遍。
-
awesome-mobx: MobX 相关资源整合,方便多看多练。
-
Mobx 源码解读(一) 基本概念:优质的 MobX 源码解读文章,受益匪浅。
-
MobX 核心源码解析:本文深入 MobX 源码来解析其核心原理以及工作流程,推荐阅读;
-
探秘 MobX:本文短小精悍,主讲
observable和autorun原理 -
MobX 原理:本文对
deviration着墨较多
—END— 
