A. 参考文档
1、教程类
-
Linked List:有代码有实现,言简意赅;
-
Data Structures With JavaScript: Singly-Linked List and Doubly-Linked List:也是优秀的教程文章,教你实现简单的单向和双向链表,看着文章敲一遍代码就会了
-
JS Data Structures: Linked List:学习链表的概念定义,这里涉及的概念比较全面,讲解了循环列表等等
-
看图轻松理解数据结构与算法系列(单向链表):该教程胜在图片示例丰富,非常适合新手;
-
The Little Guide of Linked List in JavaScript:来自 hacknoon的教程,图文并茂,只是内容并不是很全面。
-
【js4agls】数据结构JavaScript描述-链表篇:通俗易懂的入门
-
链表:行文比较 ”佛系“,不过知识点都照顾到了。比如环形链表
-
Reverse a Doubly Linked List:如何反转双向链表,附 leetcode/lintcode题解 - Reverse Linked List
-
Circular Linked List | Set 1 (Introduction and Applications):视频教程,循环列表创建和含义。
-
Why exactly do we need a “Circular Linked List” (singly or doubly) data structure?:为什么需要循环链表?
-
Find loop length in a cyclic/circular linked list:如何找到循环链表的长度,还有 Detect a loop in cyclic/circular linked list,图文并茂
-
面试精选:链表问题集锦:和链表相关的算法和问题
2、应用类
-
用链表的目的是什么?省空间还是省时间?:知乎,探讨链表的优势;
-
链表(linked list)这一数据结构具体有哪些实际应用?:知乎问答,文件系统、LRU cache 等
-
《顺序表和单链表的区别及应用场景+单链表经典例题》:本篇文章主要讲解动态顺序表与单向链表的区别与应用场景以及关于链表的一些经典例题。
-
常用数据结构的应用场景:列举了常用数据结构的应用场景。
-
Applications of Linked Lists:列举了链接的应用场景,比如存储未知长度的元素、存储稀疏矩阵等。
-
Practical Data Structures for Frontend Applications: When to use Linked Lists:介绍了链表在前端方面应用的场景,本文对比了链表和数组方面的性能,对前端程序员有很高的参考价值。
-
Javascript linked list example:在 JS 中和链表有关的应用
B. 正文
1、概念理解
正如文章 Data Structures With JavaScript: Singly-Linked List and Doubly-Linked List 中所言,链表这种数据结构非常像电视节目里的 寻宝游戏 —— 而不是 火车。
假如你设计寻宝游戏,达到指定地点后(假如你当前在北京西单)在某个特定地方放置一张纸条,该纸条上还包含了下一个你要去的地点(下一站去帽儿胡同).... 按照这种程序下去,将这些地点串接起来就形成了一个寻宝游戏。借助这个示例,就能从概念上帮你区分与数组、队列这些数据结构之间的差别。
2、链表类型
单向链表
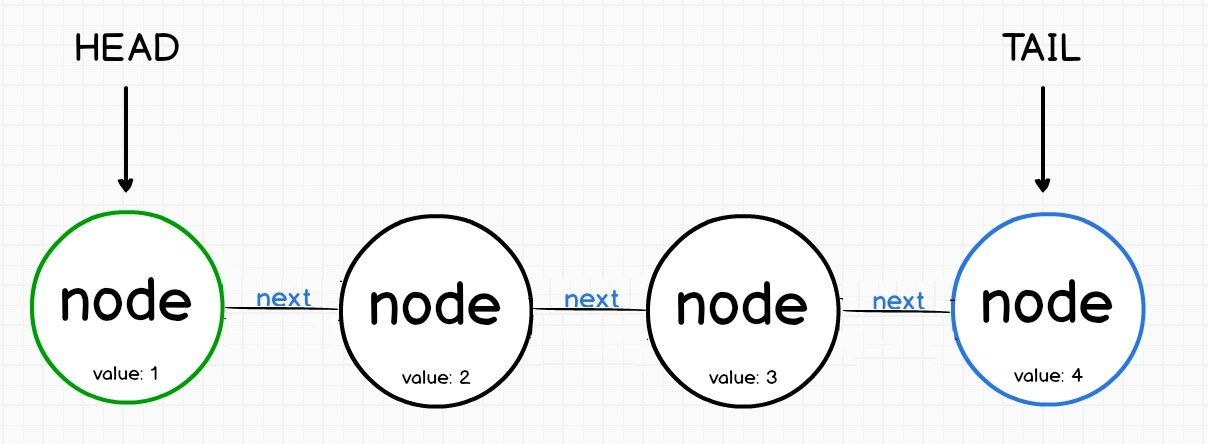
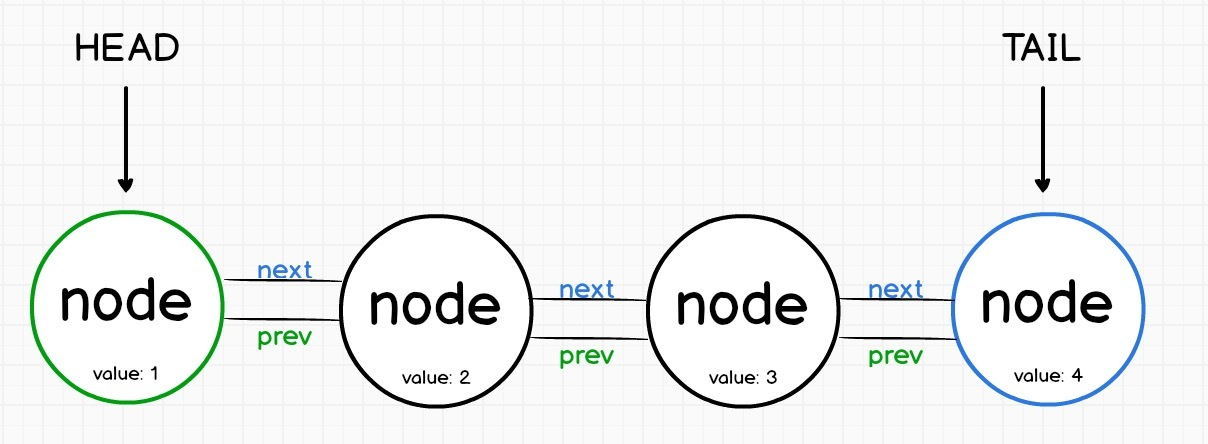
双向链表
规划数据结构细节
Node:节点类
- data: 存储任何数据
- next: 存储下一个节点(引用)
SinglyList:单向链表类 - length: 节点数量
- head: 首节点
- add(node): 在链表中添加新节点
- findNodeAt(position):检索出第 n 个节点
- remove(position): 移除某个节点
3、优缺点
主要是和数组的对比:
数组的优点是随机查找,但是在插入或者删除元素时后面的元素都会移动。而链表是由节点和数据组成,不具有随机查找的特性(链表的优缺点和数组的优缺点恰好相反)。也就是说链表查询性能比较差,修改操作比较优化。
链表中如果只是插入和删除操作,那么不会移动元素,所以会节省时间,数组的插入和删除是要移动元素的(插入和删除最后一个元素不移动);链表的查找操作是从第一个元素开始,所以相对数组要耗时间(数组直接就可以查找到)
优点:
- 动态数据结构,在程序运行时可动态创建
- 节点的新增、删除都比较容易实现
- 线性数据结构(队列、栈)都可以很容易地基于链表实现
- 因为每个节点不是空间连续的,所以链表扩张的时候几乎无内存压力。
缺点:
- 使用额外的
next属性,耗费额外的内存 - 每次链表的节点读取必须得从头到尾挨个寻找,效率不是最优
- 链表反向查找数据时比较困难,使用双向链表能够解决效率问题,但双向链表会多出
prev属性占用内存空间
总而言之,链表的用处是在特定应用场景下省时间,基本上链表不能省空间。
4、具体实现
参考现有的库:
同时还借鉴了上述参考文章的写法,最终自己编写了一个 ss-linked-list 库。该库实现了 单向链表、双向链表、单向循环链表 以及 双向循环链表。
5、应用
5.1、适用哪些场景
单向链表典型的应用场合是 各类缓冲池 和 栈 的实现,稀疏矩阵也可以用单向列表实现。
双向链表典型应用场景是各种 不需要排序的数据列表 管理
循环单向链表最典型的应用比如是系统的时间切片,给每个程序都分配一定的执行时间,然后轮到下一个。
5.2、约瑟夫环
- 第十课 — 循环链表,约瑟夫环问题的解决:使用循环链表解决约瑟夫环问题
- 循环链表应用——约瑟夫环问题
- 循环链表解决约瑟夫环问题
- 链表初解(三)——约瑟夫环之循环链表实现
可以通过在线服务 The Josephus Game 验证程序的准确性
const {CircleDoublyList} = require("ss-linked-list");
// 使用双向循环链表实现
function Josephus(n, start, k){
var numberArr = Array.from(new Array(n),(val,index)=>index+1);
var list = new CircleDoublyList(...numberArr);
var currentNode = list.getNode(start - 1);
var result = [];
while(n--){
for(var i = 0; i < k - 1; i++){
currentNode = currentNode.next;
}
result.push(currentNode.value);
currentNode.prev.next = currentNode.next;
currentNode.next.prev = currentNode.prev;
currentNode = currentNode.next;
}
return result;
}
Josephus(9, 1, 5);
// 输出结果是:[5, 1, 7, 4, 3, 6, 9, 2, 8]
另外还有单向循环列表的实现,具体都放在: https://runkit.com/boycgit/ss-linked-list
6、总结
在前端层面,应用链表的场景是比较少的,数组(Array)发挥的作用更大。链表在经常变更的大型集合(比如稀疏矩阵)中才会发挥其价值(然而这场场景是很少的),以下的场景也很合适:
- 非常频繁更改列表,增加或者删除某个列表中的元素。比如股票交易列表,需要实时将元素添加到头部;
- 不需要频繁对列表进行 读操作 的场景;
正是因为上述特性,你会发现链表经常还是其他数据结构的基础。比如堆栈、队列是频繁操作节点的,虽然使用数组可以实现,但使用链表会更加地合适。
双向列表的优势在于可以正向、逆向迭代查询,使用起来稍微比单向列表要灵活一些,但同时也稍微多占用一些内存。
